BFS와 DFS는 그래프 검색에 사용되는 통과 방법입니다. 그래프 트래버스는 그래프의 모든 노드를 방문하는 프로세스입니다. 그래프는 꼭짓점에 연결하는 Vertices 'V'와 Edges 'E'의 그룹입니다.
비교 차트
| 비교 근거 | BFS | DFS |
|---|---|---|
| 기본 | 버텍스 기반 알고리즘 | 엣지 기반 알고리즘 |
| 노드를 저장하는 데 사용되는 데이터 구조 | 열 | 스택 |
| 메모리 사용량 | 무능한 | 실력 있는 |
| 구성된 트리의 구조 | 와이드와 쇼트 | 좁고 긴 |
| 순회 패션 | 가장 오래된 unvisited 정점이 처음에 탐색됩니다. | 모서리의 정점은 처음부터 탐구됩니다. |
| 최적 성 | 비용이 아닌 최단 거리를 찾는 데 최적입니다. | 최적 상태가 아닙니다. |
| 신청 | 그래프에있는 이원 그래프, 연결된 구성 요소 및 최단 경로를 검사합니다. | 두 모서리 연결 그래프, 강하게 연결된 그래프, 비순환 그래프 및 위상차 순서를 검사합니다. |
BFS의 정의
Breadth First Search (BFS) 는 그래프에서 사용되는 통과 방법입니다. 방문 된 정점을 저장하기 위해 대기열을 사용합니다. 이 방법에서는 그래프의 꼭지점에 강조가 있고, 처음에는 하나의 꼭지점이 선택되고 방문되고 표시됩니다. 방문 된 정점에 인접한 정점이 방문되어 순차적으로 대기열에 저장됩니다. 마찬가지로, 저장된 정점은 하나씩 처리되고 인접한 정점이 방문됩니다. 노드는 그래프의 다른 노드를 방문하기 전에 완전히 탐색됩니다. 즉, 가장 얕은 미개척 노드를 먼저 통과합니다.
예
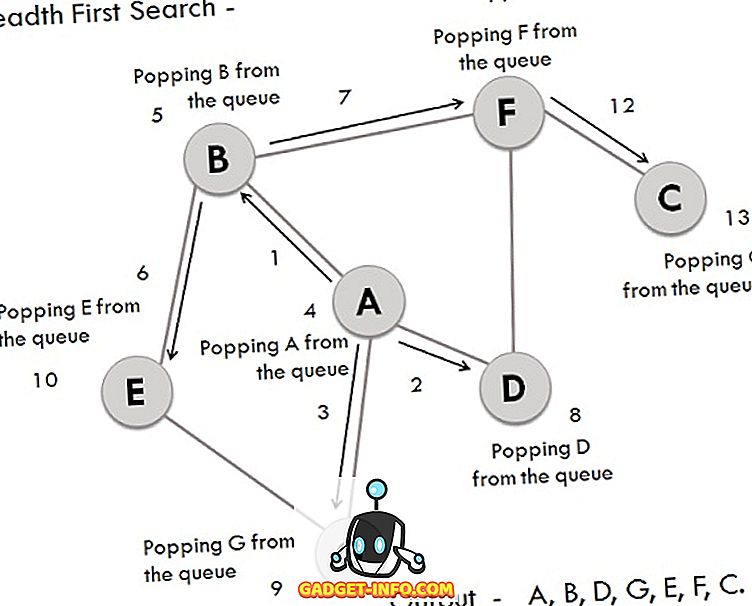
우리는 꼭지점이 A, B, C, D, E, F, G 인 그래프를 가지고 있습니다. A를 시작점으로 간주합니다. 프로세스와 관련된 단계는 다음과 같습니다.
- 정점 A가 확장되어 대기열에 저장됩니다.
- A의 정점 B, D 및 G 후속이 확장되어 정점 A가 제거되면서 대기열에 저장됩니다.
- 큐의 프런트 엔드에있는 B가 제거되어 후속 버텍스 E 및 F가 저장됩니다.
- 큐의 프런트 엔드에있는 정점 D가 제거되고 연결된 노드 F가 이미 방문되었습니다.
- 정점 G는 대기열에서 제거되고 이미 방문한 후임자 E가 있습니다.
- 이제 E와 F는 큐에서 제거되고 그 후속 버텍스 C는 가로 지르며 큐에 저장됩니다.
- 마지막으로 C도 제거되고 대기열이 비어 있습니다. 이는 우리가 완료되었음을 의미합니다.
- 생성 된 출력은 - A, B, D, G, E, F, C입니다.

BFS는 그래프에 구성 요소 가 연결 되었는지 여부를 찾는 데 유용 할 수 있습니다. 또한 이진 그래프 를 감지하는 데 사용할 수 있습니다.
그래프 정점이 두 개의 분리 된 세트로 나뉘어 질 때 그래프는 2 부분입니다. 인접한 두 정점이 같은 세트에 존재하지 않습니다. 이분 그래프를 검사하는 또 다른 방법은 그래프에서 홀수 사이클의 발생을 확인하는 것입니다. 이분 그래프는 홀수 사이클을 포함하지 않아야합니다.
BFS는 그래프에서 가장 짧은 경로 를 찾는 것이 네트워크로 간주 될 수 있습니다.
DFS의 정의
Depth First Search (DFS) 통과 방법은 방문 된 정점을 저장하기 위해 스택을 사용합니다. DFS는 에지 기반 방법이며 경로를 따라 정점을 탐색하는 재귀 방식으로 작동합니다 (에지). 탐험 노드는 탐험되지 않은 또 다른 노드가 발견되고 탐험되지 않은 가장 깊은 노드가 제일 먼저 지나가 자마자 중단됩니다. DFS는 각 꼭지점을 정확히 한번 방문하고 각 엣지를 정확하게 두 번 검사합니다.
예
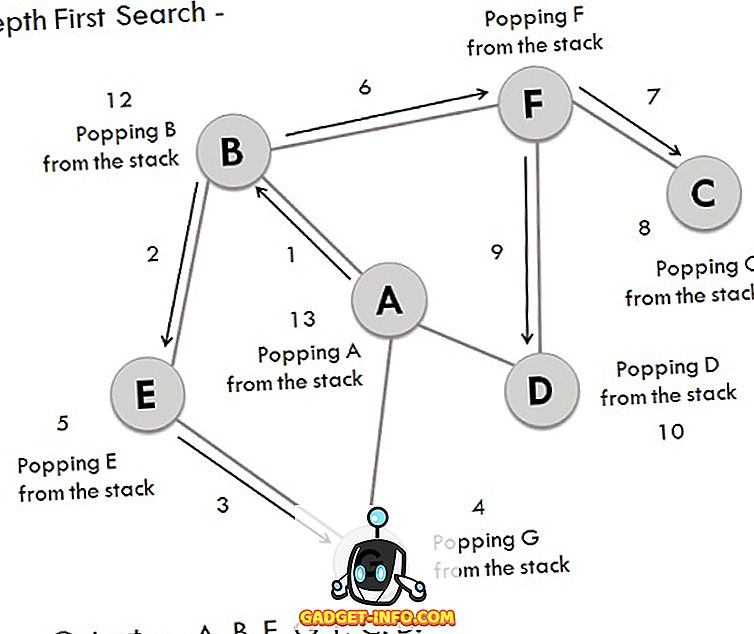
BFS와 유사하게 DFS 작업을 수행하는 데 동일한 그래프를 사용할 수 있으며 관련 단계는 다음과 같습니다.
- A를 탐색하여 스택에 저장되는 시작점으로 간주합니다.
- A의 B 후속 정점이 스택에 저장됩니다.
- 정점 B는 2 개의 후속자 E와 F를 가지며, 그 중 알파벳 순서대로 E가 먼저 탐색되어 스택에 저장됩니다.
- 정점 E의 후속, 즉 G는 스택에 저장됩니다.
- 꼭짓점 G에는 연결된 두 개의 꼭지점이 있으며 둘 다 이미 방문되어 있으므로 스택에서 G가 튀어 나옵니다.
- 마찬가지로 E도 제거됩니다.
- 이제 정점 B는 스택의 맨 위에 있고 다른 노드 (정점) F는 스택에 탐험되어 저장됩니다.
- 정점 F에는 2 개의 후속 C와 D가 있으며, C와 D 사이에는 먼저 C가 지나가고 스택에 저장됩니다.
- 버텍스 C는 이미 방문한 하나의 전임자 만 가지므로 스택에서 제거됩니다.
- 이제 F에 연결된 정점 D가 방문되어 스택에 저장됩니다.
- 정점 D에는 방문하지 않은 노드가 없으므로 D가 제거됩니다.
- 마찬가지로 F, B 및 A도 표시됩니다.
- 생성 된 출력은 -A, B, E, G, F, C, D입니다.

DFS의 응용 프로그램에는 연결된 두 개의 가장자리 연결 그래프, 강력하게 연결된 그래프, 비순환 그래프 및 위상 순서가 포함 됩니다.
그래프는 가장자리 중 하나가 제거 되더라도 연결되어있는 경우에만 연결된 두 개의 가장자리라고합니다. 이 응용 프로그램은 네트워크에서 한 링크의 오류가 나머지 네트워크에 영향을 미치지 않고 여전히 연결되어있는 컴퓨터 네트워크에서 매우 유용합니다.
강하게 연결된 그래프는 정렬 된 꼭지점 쌍 사이에 경로가 있어야하는 그래프입니다. DFS는 모든 정사각형 쌍 사이의 경로를 검색하기 위해 유향 그래프에 사용됩니다. DFS는 연결 문제를 쉽게 해결할 수 있습니다.
BFS와 DFS의 주요 차이점
- BFS는 정점 기반 알고리즘이며 DFS는 에지 기반 알고리즘입니다.
- 큐 데이터 구조는 BFS에서 사용됩니다. 반면에 DFS는 스택 또는 재귀를 사용합니다.
- 메모리 공간은 DFS에서 효율적으로 활용되지만 BFS에서 공간 활용은 효과적이지 않습니다.
- BFS는 최적 알고리즘이지만 DFS는 최적이 아닙니다.
- DFS는 좁고 긴 나무를 만듭니다. 반대로, BFS는 넓고 짧은 나무를 구성합니다.
결론
BFS와 DFS 모두 그래프 탐색 기술은 실행 시간은 비슷하지만 공간 소비는 다르지만 DFS는 미개척 노드가있는 단일 경로를 기억해야하기 때문에 선형 공간을 사용합니다. BFS는 모든 노드를 메모리에 유지합니다.
DFS는 더 깊은 솔루션을 생성하고 최적은 아니지만 솔루션이 밀집되어있을 때 잘 작동하는 반면 BFS는 처음에는 최적의 목표를 검색하는 최적입니다.