


분명히 인간과 컴퓨터 같은 전자 장치의 지각 능력은 다릅니다. 인간은 자연어를 통해 어떤 것도 이해할 수 있지만 컴퓨터는 그렇지 않습니다. 사람이 읽을 수있는 형식으로 작성된 언어를 컴퓨터가 읽을 수있는 형식으로 변환하려면 컴퓨터에 번역기가 필요합니다.
컴파일러와 인터프리터는 언어 번역기 유형입니다. 언어 번역기 란 무엇입니까? 이 질문은 당신의 마음에 발생할 수 있습니다.
언어 번역기는 사람이 읽을 수있는 형식의 소스 언어에서 프로그램을 대상 언어의 동등한 프로그램으로 변환하는 소프트웨어입니다. 소스 언어는 일반적으로 고급 프로그래밍 언어이며 객체 언어는 일반적으로 실제 컴퓨터의 기계 언어입니다.
비교 차트
| 비교 근거 | 컴파일러 | 통역사 |
|---|---|---|
| 입력 | 한 번에 전체 프로그램을 사용합니다. | 한 번에 한 줄의 코드 나 명령을 사용합니다. |
| 산출 | 중간 객체 코드를 생성합니다. | 중간 객체 코드를 생성하지 않습니다. |
| 작동 메커니즘 | 컴파일은 실행 전에 수행됩니다. | 컴파일과 실행이 동시에 일어납니다. |
| 속도 | 상대적으로 빠름 | 천천히 |
| 기억 | 메모리 요구 사항은 객체 코드 생성으로 인해 더 많습니다. | 중간 객체 코드를 생성하지 않기 때문에 메모리가 덜 필요합니다. |
| 오류 | 컴파일 후 모든 오류를 동시에 표시하십시오. | 각 행의 오류를 하나씩 표시합니다. |
| 오류 감지 | 어려운 | 상대적으로 쉽게 |
| 관련 프로그래밍 언어 | C, C ++, C #, Scala, typescript는 compiler를 사용합니다. | Java, PHP, Perl, Python, Ruby는 인터프리터를 사용합니다. |
컴파일러의 정의
컴파일러는 고급 언어로 작성된 프로그램을 읽고 기계 또는 저급 언어로 변환하고 프로그램에있는 오류를보고하는 프로그램입니다. 한 번에 전체 소스 코드를 변환하거나 그렇게하기 위해 다중 패스를 취할 수 있지만, 마침내 사용자는 실행할 준비가 된 컴파일 된 코드를 얻습니다.

컴파일러는 단계별로 작동합니다. 다양한 스테이지는 다음과 같은 두 부분으로 그룹화 할 수 있습니다.
- 컴파일러의 분석 단계 는 프로그램이 기본 구성 요소로 나누어지고 중간 코드가 생성 된 후 코드의 문법, 의미 및 구문을 검사하는 프런트 엔드라고도합니다. 분석 단계에는 어휘 분석기, 의미 분석기 및 구문 분석기가 포함됩니다.
- 컴파일러의 합성 단계 는 중간 코드가 최적화되고 대상 코드가 생성되는 백엔드라고도합니다. 합성 단계에는 코드 옵티 마이저와 코드 생성기가 포함됩니다.
컴파일러의 위상
이제 각 단계의 작업을 자세히 이해합시다.
- 어휘 분석기 : 코드를 문자 스트림으로 스캔하고 문자 시퀀스를 어휘로 그룹화 한 다음 프로그래밍 언어를 참조하여 일련의 토큰을 출력합니다.
- 구문 분석기 :이 단계에서는 이전 단계에서 생성 된 토큰이 구문이 올바른지 여부에 관계없이 프로그래밍 언어의 문법에 대해 검사됩니다. 이렇게하면 구문 분석 트리가됩니다.
- Semantic Analyzer : 이전 단계에서 생성 된 표현식과 문장이 프로그래밍 언어의 규칙을 따르는 지 여부를 확인하고 주석이 달린 구문 분석 트리를 생성합니다.
- 중간 코드 생성기 : 소스 코드의 중간 코드를 생성합니다. 중간 코드의 표현은 많이 있지만 TAC (Three Address Code)는 가장 널리 사용됩니다.
- 코드 최적화 : 프로그램의 시간 및 공간 요구 사항을 향상시킵니다. 그렇게하기 위해 프로그램에있는 중복 코드를 제거합니다.
- 코드 생성기 : 특정 컴퓨터에 대한 대상 코드가 생성되는 컴파일러의 최종 단계입니다. 메모리 관리, 레지스터 할당 및 머신 특정 최적화와 같은 연산을 수행합니다.
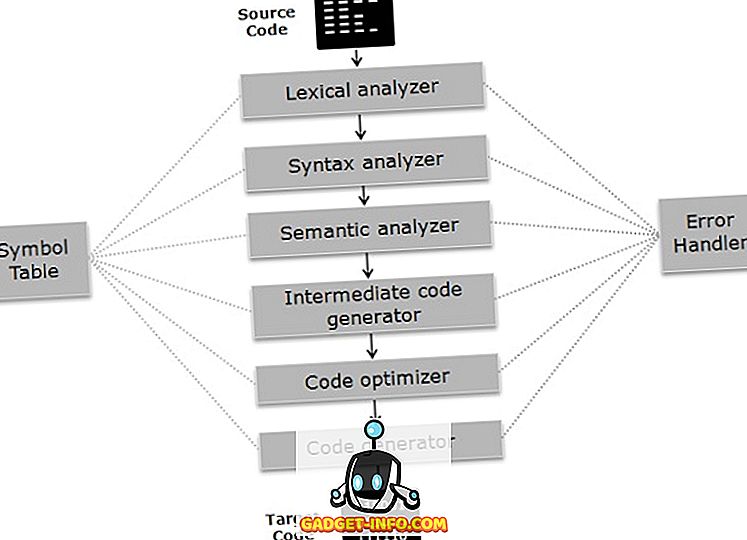
심볼 테이블 은 저장하는 관련 데이터 유형과 함께 식별자를 관리하는 데이터 구조입니다. 오류 처리기 는 컴파일러의 여러 단계에서 발생하는 오류를 감지, 보고 및 수정합니다.
통역사의 정의
인터프리터는 프로그래밍 언어를 구현하기위한 대안이며 컴파일러와 동일한 작업을 수행합니다. 인터프리터는 컴파일러와 비슷한 렉싱, 구문 분석 및 형식 검사를 수행합니다. 그러나 인터프리터는 구문 트리를 직접 처리하여 구문 트리에서 코드를 생성하는 대신 표현식에 액세스하고 명령문을 실행합니다.
해석자는 동일한 구문 트리를 두 번 이상 처리해야 할 수도 있습니다. 이는 해석이 컴파일 된 프로그램을 실행하는 것보다 상대적으로 느린 이유입니다.
컴파일과 해석이 결합되어 프로그래밍 언어를 구현할 수 있습니다. 컴파일러가 중급 수준의 코드를 생성하는 경우 코드는 컴퓨터 코드로 컴파일되기보다는 해석됩니다.
통역사를 고용하는 것은 프로그램 개발 중에 유리합니다. 가장 중요한 부분은 프로그램을 효율적으로 실행하기보다는 프로그램 수정을 빠르게 테스트 할 수있는 것입니다.
컴파일러와 인터프리터의 주요 차이점
컴파일러와 인터프리터의 주요 차이점을 살펴 보겠습니다.
- 컴파일러는 프로그램 전체를 가져 와서 해석하지만, 인터프리터는 명령문으로 프로그램 명령문을 해석합니다.
- 중간 코드 또는 타겟 코드는 컴파일러의 경우에 생성됩니다. 인터프리터와 달리 중간 코드를 생성하지 않습니다.
- 컴파일러는 컴파일러가 한 번에 전체 프로그램을 사용하기 때문에 인터프리터보다 상대적으로 빠릅니다. 반면 인터프리터는 다른 프로그램 다음에 각 코드 행을 컴파일합니다.
- 컴파일러는 객체 코드 생성 때문에 인터프리터보다 많은 메모리를 필요로합니다.
- 컴파일러는 모든 오류를 동시에 표시하므로 각 구문의 명암 인터프리터 표시 오류에서 오류를 하나씩 감지하기가 어렵고 오류를 쉽게 감지 할 수 있습니다.
- 컴파일러에서는 프로그램에서 에러가 발생하면 번역을 중지하고 에러를 제거한 후 전체 프로그램을 다시 번역합니다. 반대로, 인터프리터에서 오류가 발생하면 오류가 제거되고 오류가 제거 된 후 번역이 다시 시작됩니다.
- 컴파일러에서 프로세스는 두 단계를 거쳐 먼저 소스 코드가 대상 프로그램으로 변환 된 후 실행됩니다. Interpreter에서 동시에 소스 코드가 컴파일되고 실행되는 한 단계 프로세스입니다.
- 컴파일러는 C, C ++, C #, Scala 등과 같은 프로그래밍 언어에서 사용됩니다. 다른 인터프리터는 Java, PHP, Ruby, Python 등과 같은 언어로 사용됩니다.
결론
컴파일러와 인터프리터는 모두 동일한 작업을 수행하지만 조작 절차가 다르므로 컴파일러는 소스 코드를 집계 한 반면에 인터프리터는 소스 코드의 구성 부분 (예 : 명령문)을 사용합니다.
컴파일러와 인터프리터 모두 통역 언어와 같은 특정 장단점을 가지고 있지만 크로스 플랫폼으로 간주됩니다. 즉 코드는 이식성이 있습니다. 또한 컴파일러와 달리 시간을 절약 할 수있는 명령어를 컴파일 할 필요가 없습니다. 컴파일 된 언어는 컴파일 프로세스와 관련하여 더 빠릅니다.