



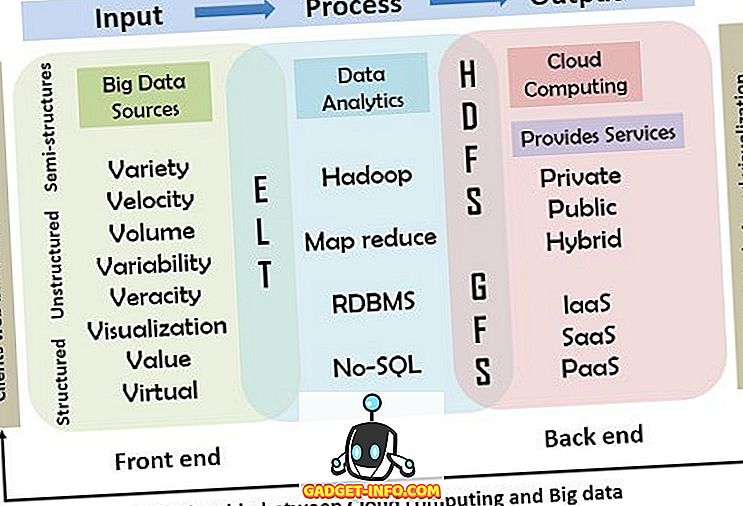
여기에는 아래에서 설명하는 입력, 처리 및 출력 모델이 포함됩니다. 이 다이어그램은 클라우드 컴퓨팅과 빅 데이터 간의 관계를 자세히 보여줍니다.
비교 차트
| 비교 근거 | 클라우드 컴퓨팅 | 빅 데이터 |
|---|---|---|
| 기본 | 주문형 서비스는 통합 컴퓨터 자원 및 시스템을 사용하여 제공됩니다. | 전통적인 처리 기술을 사용하지 못하게하는 구조화 된, 구조화되지 않은 복잡한 데이터의 광범위한 세트. |
| 목적 | 데이터를 원격 서버에서 저장 및 처리하고 어느 곳에서나 액세스 할 수 있습니다. | 대량의 데이터 및 정보의 조직은 숨겨진 가치있는 지식을 추출합니다. |
| 일 | 분산 컴퓨팅은 데이터를 분석하고보다 유용한 데이터를 생성하는 데 사용됩니다. | 인터넷은 클라우드 기반 서비스를 제공하는 데 사용됩니다. |
| 장점 | 낮은 유지 보수 비용, 중앙 집중식 플랫폼, 백업 및 복구 제공. | 비용 효율적인 병렬 처리, 확장 가능하고 강력한. |
| 도전 과제 | 가용성, 변환, 보안, 요금 부과 모델. | 데이터 다양성, 데이터 저장, 데이터 통합, 데이터 처리 및 리소스 관리. |
클라우드 컴퓨팅의 정의
클라우드 컴퓨팅 은 초고속 인터넷을 사용하여 언제 어디서나 필요한 모든 양의 데이터를 저장하고 검색 할 수있는 통합 된 서비스 플랫폼을 제공합니다. 클라우드는 데이터를 저장, 관리 및 처리하기 위해 인터넷에 분산되어있는 광범위한 지상 서버입니다. 클라우드 컴퓨팅은 개발자가 웹 규모 컴퓨팅을 쉽게 구현할 수 있도록 개발되었습니다. 인터넷의 진화는 인터넷이 클라우드 컴퓨팅의 기초이기 때문에 클라우드 컴퓨팅 모델을 양조합니다. 클라우드 컴퓨팅을 효율적으로 작동 시키려면 고속 인터넷 연결이 필요합니다. 용량과 기능을 동적으로 추가 할 수있는 유연한 환경을 제공하며 사용 당 비용 전략에 따라 사용됩니다.
클라우드 컴퓨팅은 리소스 풀링, 주문형 셀프 서비스, 광범위한 네트워크 액세스, 측정 된 서비스 및 빠른 탄력성과 같은 몇 가지 필수 속성을 가지고 있습니다. 클라우드에는 공개, 비공개, 하이브리드 및 커뮤니티의 네 가지 유형이 있습니다.
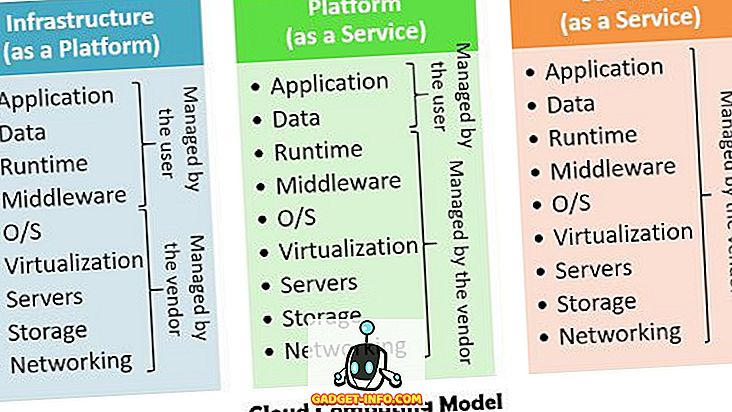
기본적으로 서비스 (Paas), 서비스 (Iaas), 소프트웨어 (SaaS)의 3 가지 클라우드 컴퓨팅 모델이 있으며 하드웨어 및 소프트웨어 서비스를 사용합니다.
- 인프라로서의 서비스 -이 서비스는 스토리지 처리 능력과 가상 시스템을 포함하는 인프라를 제공하는 데 사용됩니다. SLA (Service Level Agreement)를 토대로 자원 가상화를 구현합니다.
- 서비스 형태의 플랫폼 - 사용자가 클라우드 애플리케이션을 배포 할 수 있도록 프로그래밍 및 런타임 환경을 제공하는 IaaS 계층 위에 위치합니다.
- 서비스로서의 소프트웨어 - 클라우드 공급자에서 직접 실행되는 클라이언트에 응용 프로그램을 전달합니다.

빅 데이터의 정의
데이터는 볼륨, 다양성, 속도의 증가로 IT 시스템의 능력을 넘어서는 큰 데이터 로 변하게되며, 결과적으로 데이터 저장, 분석 및 처리가 어려워집니다. 일부 조직에서는 이러한 유형의 엄청난 양의 구조화 된 데이터를 처리 할 수있는 장비와 전문 지식을 개발했지만 기하 급수적으로 증가하는 데이터의 양과 신속한 데이터 흐름은 데이터를 수집하고 즉시 조치 할 수있는 인텔리전스를 생성하는 기능을 중단시킵니다. 이 방대한 데이터는 일반 장치에 저장하거나 분산 환경에 분산시킬 수 없습니다. 빅 데이터 컴퓨팅은 대규모 인프라에서의 과학적 발견 및 비즈니스 분석을 위해 다차원 정보 마이닝에 중점을 둔 데이터 과학 의 초기 개념입니다.
빅 데이터의 기본 차원은 볼륨, 속도, 다양성 및 진실성이며 위에서 언급 한 바와 같이 나중에 가변성과 가치 인 두 가지 차원이 더 발전했습니다.
- 볼륨 - 이미 처리하고 저장하는 데 문제가있는 데이터의 증가하는 크기를 나타냅니다.
- 속도 - 데이터가 캡처되는 인스턴스 및 데이터 흐름의 속도입니다.
- 다양성 - 데이터가 단일 형식으로 항상 존재하지는 않습니다. 텍스트, 오디오, 이미지 및 비디오와 같은 다양한 형태의 데이터가 있습니다.
- Veracity - 데이터의 신뢰성이라고합니다.
- 가변성 - 빅 데이터에서 생성되는 신뢰성, 복잡성 및 불일치를 설명합니다.
- 가치 - 원래 형식의 콘텐츠가 유용하고 생산적이지 않을 수 있으므로 데이터가 분석되고 높은 가치의 데이터가 발견됩니다.
클라우드 컴퓨팅과 빅 데이터의 주요 차이점
- 클라우드 컴퓨팅은 인터넷을 통해 분산 된 컴퓨팅 리소스를 사용하여 필요할 때 제공되는 컴퓨팅 서비스입니다. 반면에 큰 데이터는 전통적인 알고리즘과 기법으로는 처리 할 수없는 구조화 된, 구조화되지 않은, 반 구조화 된 데이터를 포함하는 엄청난 양의 컴퓨터 데이터입니다.
- 클라우드 컴퓨팅은 수요에 따라 Saas, Paas 및 Iaas와 같은 서비스를 사용할 수있는 플랫폼을 사용자에게 제공하며 사용에 따라 서비스 요금을 청구합니다. 대조적으로, 큰 데이터의 주요 목적은 엄청난 양의 데이터로부터 숨겨진 지식과 패턴을 추출하는 것입니다.
- 고속 인터넷 연결은 클라우드 컴퓨팅의 필수 요건입니다. 이와 반대로 빅 데이터는 데이터를 분석하고 마이닝하기 위해 분산 컴퓨팅을 사용합니다.
클라우드 컴퓨팅과 빅 데이터 간의 관계
아래 그림은 큰 데이터로 클라우드 컴퓨팅의 관계와 작업을 보여줍니다. 이 모델에서 기본 입력, 처리 및 출력 컴퓨팅 모델은 마우스, 키보드, 휴대 전화 및 기타 스마트 장치와 같은 입력 장치를 사용하여 시스템에 큰 데이터가 삽입되는 참조 용으로 사용됩니다. 처리의 두 번째 단계에는 클라우드에서 서비스를 제공하기 위해 사용하는 도구와 기술이 포함됩니다. 마지막으로 처리 결과가 사용자에게 전달됩니다.
결론
클라우드 컴퓨팅 기술은 사용 용이성, 자원에 대한 액세스, 공급 및 수요에 대한 자원 사용의 비용 절감, 큰 데이터 처리에 사용되는 견고한 장비의 사용 최소화를 통해 대용량 데이터에 적합하고 호환되는 프레임 워크를 제공합니다. 클라우드와 빅 데이터 모두 기업의 가치를 높이는 동시에 투자 비용을 줄이는 데 중점을 둡니다.






