두 가지 정렬 기법, 빠른 정렬 및 병합 정렬은 요소 세트가 분리 된 다음 다시 정렬 된 후 분할 및 정복 방법을 기반으로합니다. 빠른 정렬은 일반적으로 큰 요소 집합을 정렬하기 위해 병합 정렬보다 더 많은 비교를 요구합니다.
비교 차트
| 비교 근거 | 빠른 정렬 | Merge sort |
|---|---|---|
| 배열 요소의 파티셔닝 | 요소 목록의 분할은 반드시 반으로 분할되지는 않습니다. | 배열은 항상 절반 (n / 2)으로 나뉩니다. |
| 최악의 경우의 복잡성 | O (n2) | O (n log n) |
| 잘 작동합니다. | 더 작은 배열 | 모든 유형의 어레이에서 정상적으로 작동합니다. |
| 속도 | 작은 데이터 세트를위한 다른 정렬 알고리즘보다 빠릅니다. | 모든 유형의 데이터 세트에서 일관된 속도. |
| 추가 저장 공간 요구 사항 | 적게 | 더 |
| 능률 | 큰 배열의 경우 비효율적입니다. | 보다 효율적입니다. |
| 정렬 방법 | 내부의 | 외부 |
빠른 정렬의 정의
빠른 정렬 은 짧은 배열에 대해 빠르기 때문에 널리 사용되는 정렬 알고리즘입니다. 요소 집합은 더 이상 나눌 수 없을 때까지 반복적으로 여러 부분으로 나뉩니다. 빠른 정렬은 파티션 교환 정렬 이라고도 합니다 . 요소를 분할 할 때 핵심 요소 (피벗이라고 함)를 사용합니다. 하나의 파티션에는 핵심 요소보다 작은 요소가 들어 있습니다. 다른 파티션에는 핵심 요소보다 큰 요소가 포함되어 있습니다. 요소는 재귀 적으로 정렬됩니다.
A가 정렬되어야하는 n 개의 숫자의 배열 A [1], A [2], A [3], ..., A [n]이라고하자. 빠른 정렬 알고리즘은 다음 단계로 구성됩니다.
- 첫 번째 요소 또는 임의의 요소를 키로 선택하면 키 = A (1)로 가정합니다.
- "낮은"포인터는 두 번째 포인터에 배치되고 "위"포인터는 배열의 마지막 요소, 즉 low = 2 및 up = n에 위치합니다.
- 지속적으로 "낮음"포인터를 한 위치만큼 증가시킵니다 (A [낮음]> 키).
- 끊임없이 (A [위로] <= 키까지) "위"포인터를 한 위치 씩 감소시킵니다.
- 업이 낮은 인터체인지보다 큰 경우 A [낮음]과 A [위로].
- 5 단계의 조건이 실패 할 때까지 3, 4, 5 번 단계를 반복합니다 (예 : 위로 <= 낮음). 그런 다음 A [위로] 키를 교환합니다.
- 키의 왼쪽에있는 요소가 키보다 작고 키 오른쪽의 요소가 키보다 크면 배열은 두 개의 하위 배열로 분할됩니다.
- 위의 절차는 전체 배열이 정렬 될 때까지 반복적으로 하위 배열에 적용됩니다.


장점과 단점
좋은 평균적인 행동을합니다. 빠른 정렬의 실행 시간 복잡성은 버블 정렬, 삽입 정렬 및 선택 정렬과 같은 알고리즘보다 빠릅니다. 그러나, 그것은 복잡하고 매우 재귀 적이기 때문에 큰 배열에 적합하지 않습니다.
병합 정렬 정의
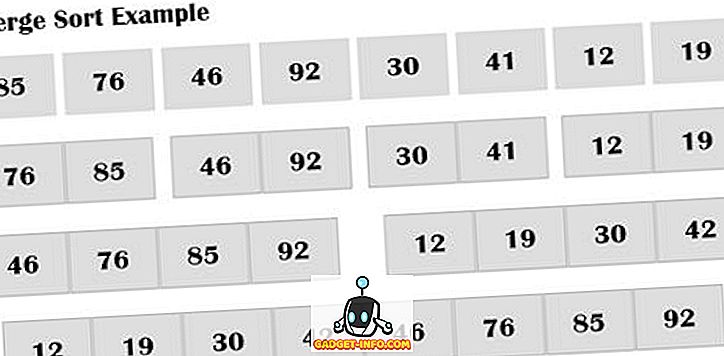
병합 정렬 은 분할 및 정복 전략을 기반으로하는 외부 알고리즘입니다. 요소는 하나의 요소가 남을 때까지 하위 배열 (n / 2)로 다시 나누어지며 정렬 시간이 현저하게 줄어 듭니다. 보조 어레이를 저장하기 위해 추가 스토리지를 사용합니다. Merge sort는 세 개의 배열을 사용하는데 두 개는 각 반을 저장하는 데 사용되고 세 번째 배열은 최종 정렬 된 목록을 저장하는 데 사용됩니다. 각 배열은 재귀 적으로 정렬됩니다. 마지막으로 배열의 요소 크기를 만들기 위해 하위 배열을 병합합니다. 목록은 항상 빠른 정렬과 다른 절반 (n / 2)으로 나뉩니다.
A를 A [1], A [2], ........., A [n]으로 정렬되는 n 개의 요소 수의 배열이라고하자. 병합 정렬은 주어진 단계를 따릅니다.
- (A [1], A [2]), (A [3], A [4]), (A [3], A [4])에있는 요소가 2로 정렬 된 약 n / 2 정렬 된 하위 배열로 배열 A를 나눕니다. k], A [k + 1]), (A [n-1], A [n]) 서브 어레이는 정렬 된 순서로 존재해야한다.
- 각 쌍의 쌍을 결합하여 크기가 4 인 정렬 된 하위 배열 목록을 얻습니다. (A [1], A [2], A [3], A [4]), ..., (A [k-1], A [k], A A [n-3], A [n-2], A [n-1], A [n])을 생성한다.
- 단계 2는 크기 n의 정렬 된 배열이 하나만있을 때까지 반복적으로 수행됩니다.

장점과 단점
병합 정렬 알고리즘은 정렬에 관련된 요소의 수에 관계없이 정확히 동일하고 정확하게 수행합니다. 큰 데이터 세트로도 잘 작동합니다. 그러나 메모리의 많은 부분을 소모합니다.
빠른 정렬과 병합 정렬 간의 주요 차이점
- 병합 정렬에서 배열은 두 개의 반쪽 (예 : n / 2)으로 분리되어야합니다. 반대로, 빠른 정렬에서는 목록을 동등한 요소로 나눌 필요가 없습니다.
- 빠른 정렬의 최악의 경우의 복잡도는 최악의 조건에서 훨씬 더 많은 비교가 필요하므로 O (n2)입니다. 대조적으로, 병합 정렬은 동일한 최악의 경우와 평균 사례 복잡성, 즉 O (n log n)을 갖습니다.
- 병합 정렬은 크거나 작은 모든 유형의 데이터 세트에서 잘 작동 할 수 있습니다. 반대로, 빠른 정렬은 대형 데이터 세트에서 제대로 작동하지 않습니다.
- 작은 데이터 세트와 같은 경우에는 빠른 정렬이 병합 정렬보다 빠릅니다.
- Merge sort는 보조 배열을 저장하기 위해 추가 메모리 공간이 필요합니다. 반면에 빠른 정렬은 추가 저장 공간을 필요로하지 않습니다.
- 병합 정렬은 빠른 정렬보다 효율적입니다.
- 빠른 정렬은 정렬 할 데이터가 주 메모리에서 한 번에 조정되는 내부 정렬 방법입니다. 반대로 병합 정렬은 정렬 할 데이터를 동시에 메모리에 저장할 수없고 일부는 보조 메모리에 보관해야하는 외부 정렬 방법입니다.
결론
빠른 정렬은 더 빠른 경우이지만 일부 상황에서는 비효율적이며 병합 정렬과 비교할 때 많은 비교를 수행합니다. 병합 정렬은 비교가 덜 필요하지만 빠른 정렬에는 O (log n)의 공간이 필요하지만 추가 배열을 저장하는 데는 0 (n)의 추가 메모리 공간이 필요합니다.