기본적으로 배열은 공통 표제 또는 변수 이름으로 순차적 메모리 위치에 저장된 유사한 데이터 객체 집합입니다.
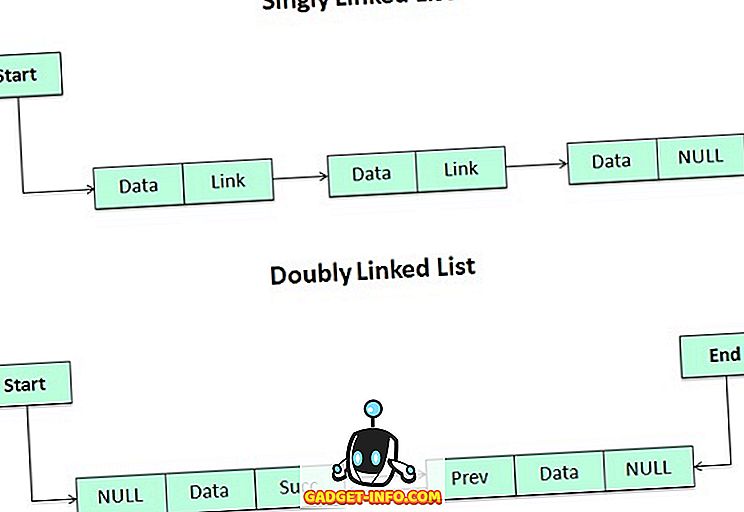
연결된 목록은 각 요소가 다음 요소에 링크되는 요소의 시퀀스를 포함하는 데이터 구조입니다. 연결된 목록의 요소에는 두 개의 필드가 있습니다. 하나는 데이터 필드이고, 다른 하나는 링크 필드이며, 데이터 필드는 저장되고 처리 될 실제 값을 포함합니다. 또한 링크 필드는 링크 된 목록의 다음 데이터 항목의 주소를 보유합니다. 특정 노드에 액세스하는 데 사용되는 주소를 포인터라고합니다.
배열과 연결된 목록 간의 또 다른 중요한 차이점은 배열 크기가 고정되어 있으며 이전에 선언해야한다는 점입니다. 그러나 링크 된 목록은 실행 중에 크기와 확장 및 축소에 국한되지 않습니다.
비교 차트
| 비교의 근거 | 정렬 | 연결된 목록 |
|---|---|---|
| 기본 | 고정 된 수의 데이터 항목의 일관된 집합입니다. | 다양한 수의 데이터 항목을 포함하는 순서가 지정된 집합입니다. |
| 크기 | 선언 중에 지정됩니다. | 지정할 필요가 없습니다. 실행 중 성장 및 축소. |
| 스토리지 할당 | 요소 위치는 컴파일하는 동안 할당됩니다. | 요소 위치는 런타임 중에 지정됩니다. |
| 요소의 순서 | 연속적으로 저장 됨 | 무작위로 저장 됨 |
| 요소에 액세스하기 | 직접 또는 무작위로 액세스합니다 (예 : 배열 색인 또는 첨자 지정). | 순차적으로 액세스됩니다. 즉, 목록의 첫 번째 노드부터 시작하여 포인터로 트래버스합니다. |
| 요소의 삽입 및 삭제 | 상대적으로 천천히 변속해야합니다. | 더 쉽고 빠르며 효율적입니다. |
| 수색 | 이진 검색 및 선형 검색 | 선형 검색 |
| 필요한 메모리 | 적게 | 더 |
| 메모리 사용률 | 효과적인 | 실력 있는 |
배열의 정의
배열은 일정한 수의 동종 요소 또는 데이터 항목 집합으로 정의됩니다. 즉, 배열에는 모든 정수, 모든 부동 소수점 숫자 또는 모든 문자 중 하나의 데이터 유형 만 포함될 수 있습니다. 배열의 선언은 다음과 같습니다 :
int a [10];
여기서 int는 데이터 유형을 지정하거나 요소 배열에 저장합니다. "a"는 배열의 이름이고 대괄호 안에 지정된 숫자는 배열이 저장할 수있는 요소의 수입니다. 배열의 크기 또는 길이라고도합니다.
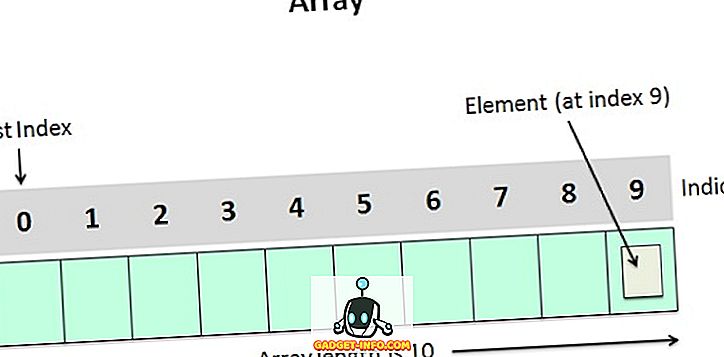
배열에 대해 기억해야 할 몇 가지 개념을 살펴 보겠습니다.
- 배열의 개별 요소는 대괄호 안에 배열의 이름을 기술하고 인덱스 또는 아래 첨자 (배열에서 요소의 위치를 결정)를 통해 액세스 할 수 있습니다. 예를 들어 배열의 다섯 번째 요소를 검색하려면 a [4] 문을 작성해야합니다.
- 어쨌든 배열 요소는 연속적인 메모리 위치에 저장됩니다.
- 배열의 첫 번째 요소는 인덱스 0 [0]을가집니다. 첫 번째 요소와 마지막 요소는 각각 [0]과 a [9]로 지정됩니다.
- 배열에 저장할 수있는 요소의 수, 즉 배열의 크기 또는 길이는 다음 방정식에 의해 제공됩니다.
(상한 - 하한) + 1
위의 배열의 경우, (9-0) + 1 = 10이됩니다. 여기서 0은 배열의 하한이고 9는 배열의 상한입니다. - 배열은 루프를 통해 읽고 쓸 수 있습니다. 1 차원 배열을 읽는다면 읽기를위한 루프와 배열 쓰기 (인쇄)를위한 루프가 필요합니다. 예를 들면 다음과 같습니다.
에이. 배열 읽기
for (i = 0; i <= 9; i ++)
{scanf ( "% d", & a [i]); }
비. 배열 쓰기
for (i = 0; i <= 9; i ++)
{printf ( "% d", a [i]); } - 2D 배열의 경우에는 두 개의 루프가 필요하며 마찬가지로 n 차원 배열에는 n 개의 루프가 필요합니다.
배열에서 수행되는 연산은 다음과 같습니다.
- 배열 생성
- 배열 탐색
- 새로운 요소의 삽입
- 필수 요소를 삭제합니다.
- 요소의 수정.
- 배열 병합
예
다음 프로그램은 배열의 읽기 및 쓰기를 보여줍니다.
#include #include void main () { int a[10], i; printf("Enter the array"); for ( i= 0; i <= 9; i++) { scanf ( "%d", &a[ i ] ) ; } printf( "Enter the array" ); for (i = 0 ; i <= 9 ; i++) { printf ( "%d\n", a[ i ] ) ; } getch (); }
링크 된 목록의 정의
링크 된 목록은 서로 연결된 일부 데이터 요소의 특정 목록입니다. 이 모든 요소에서 논리적 순서를 나타내는 다음 요소를 가리 킵니다. 각 요소는 두 부분으로 구성된 노드라고합니다.
정보를 저장하는 INFO 부분과 다음 요소를 가리키는 POINTER. 주소를 저장하는 방법을 알고 있듯이 C라는 포인터로 불리는 고유 한 데이터 구조가 있습니다. 따라서 목록의 두 번째 필드는 포인터 유형이어야합니다.
링크 된 목록의 유형은 단독 연결 목록, 이중 연결 목록, 순환 연결 목록, 순환 이중 연결 목록입니다.
연결된 목록에서 수행되는 작업은 다음과 같습니다.
- 창조
- 이동
- 삽입
- 삭제
- 수색
- 연쇄
- 디스플레이
예
다음 스 니펫은 연결 목록 생성을 보여줍니다.
struct node { int num; stuct node *next; } start = NULL; void create() { typedef struct node NODE; NODE *p, *q; char choice; first = NULL; do { p = (NODE *) malloc (sizeof (NODE)); printf ("Enter the data item\n"); scanf ("%d", & p -> num); if (p == NULL) { q = start; while (q -> next ! = NULL) { q = q -> next } p -> next = q -> next; q -> = p; } else { p -> next = start; start = p; } printf ("Do you want to continue (type y or n) ? \n"); scanf ("%c", &choice) ; } while ((choice == 'y') || (choice == 'Y')); }
배열과 링크 된 목록의 주요 차이점
- 배열은 유사한 유형의 데이터 요소의 집합을 포함하는 데이터 구조입니다. 반면 링크 된 목록은 노드라고하는 순서가 지정되지 않은 링크 된 요소의 컬렉션을 포함하는 비 프리미티브 데이터 구조로 간주됩니다.
- 배열에서 요소는 인덱스에 속합니다. 즉, 네 번째 요소로 들어가려면 변수 이름을 해당 인덱스 또는 위치와 함께 대괄호 안에 써야합니다.
그러나 링크 된 목록에서 머리에서 시작하여 네 번째 요소에 도달 할 때까지 작업해야합니다. - 요소 목록에 액세스하는 것은 빠르지 만 링크 된 목록은 선형 시간이 걸리므로 상당히 느립니다.
- 배열에서의 삽입 및 삭제와 같은 작업은 많은 시간을 소비합니다. 반면에 Linked 목록에서 이러한 작업의 성능은 빠릅니다.
- 배열의 크기는 고정되어 있습니다. 반대로 링크 된 목록은 동적이며 유연하며 크기를 확장하거나 축소 할 수 있습니다.
- 배열에서 메모리는 컴파일 타임에 할당되는 반면, 링크 된리스트에서는 실행 또는 런타임 중에 할당됩니다.
- 요소는 배열로 연속적으로 저장되는 반면 링크 된 목록에는 무작위로 저장됩니다.
- 배열의 색인 내에 실제 데이터가 저장되기 때문에 메모리 요구량이 적습니다. 반대로, 다음 및 이전 참조 요소를 추가로 저장하기 때문에 연결된 목록에 더 많은 메모리가 필요합니다.
- 또한 메모리 사용률은 어레이에서 비효율적입니다. 반대로, 메모리 활용도는 배열에서 효율적입니다.
결론
배열 및 링크 된 목록은 구조, 액세스 및 조작 방법, 메모리 요구 사항 및 사용량이 다른 데이터 구조 유형입니다. 그리고 그 구현보다 특별한 이점과 단점이 있습니다. 따라서 필요에 따라 둘 중 하나를 사용할 수 있습니다.