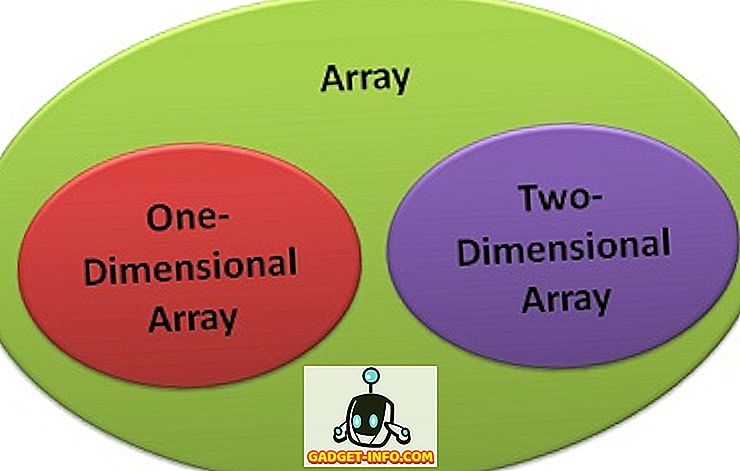
먼저 비교 차트와 함께 1 차원 및 2 차원 배열의 차이점부터 살펴 보겠습니다.
비교 차트 :
| 비교의 근거 | 일차원 | 2 차원 |
|---|---|---|
| 기본 | 유사한 데이터 유형의 요소들로 된 단일 목록을 저장하십시오. | '목록 목록'또는 '배열 배열'또는 '1 차원 배열 배열'을 저장하십시오. |
| 선언 | C ++에서 / * 선언 변수 이름 [크기]; * / / * Java에서의 선언 변수 이름 []; variable_name = 새 유형 [크기]; * / | C ++에서 / * 선언 variable_name을 입력하십시오 [size1] [size2]; * / / * Java에서의 선언 variable_name 유형 = 새 int [크기 1] [크기 2]; * / |
| 대체 선언 | / * Java에서 int [] a = 새로운 int [10]; * / | / * Java에서 int [] [] a = 새 int [10] [20]; * / |
| 총 크기 (바이트) | 총 바이트 = sizeof (배열 변수의 데이터 유형) * 배열의 크기입니다. | 총 바이트 = sizeof (배열 변수의 데이터 유형) * 첫 번째 인덱스의 크기 * 두 번째 인덱스의 크기. |
| 수신 매개 변수 | 포인터, 크기가 지정된 배열 또는 크기가 조정되지 않은 배열로 수신 될 수 있습니다. | 매개 변수를 수신하면 배열의 가장 오른쪽 치수를 정의해야합니다. |
| 치수 | 1 차원. | 2 차원. |
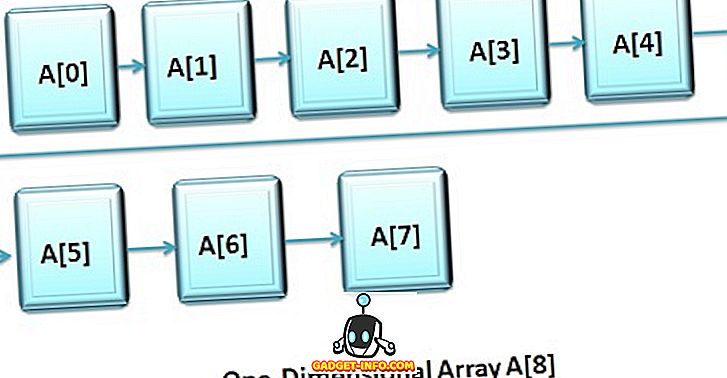
1 차원 배열의 정의 (일차원 배열)
일차원 또는 일차원 배열은 "유사한 데이터 유형의 변수 목록"으로 간주되며 각 변수는 해당 배열의 이름 앞에 대괄호 안에 색인을 지정하여 명확하게 액세스 할 수 있습니다.
C ++ 컨텍스트에서 설명합시다.
// C ++에서의 선언 variable_name [size];
여기서 type은 배열 변수의 데이터 유형을 선언하고 size는 배열이 보유 할 요소의 수를 정의합니다.
예를 들어, 한 해의 각 달의 잔액을 포함하는 배열을 선언하고자하는 경우.
// 예제 int month_balance [12];
Month _balance는 각 달의 잔액을 나타내는 12 개의 정수를 보유 할 배열 변수입니다. 이제 우리가 4 월의 '4 월'의 잔액에 액세스하기를 원한다면, 변수 이름과 4 월의 월 인덱스 값인 'month_balance [3]'을 포함하는 대괄호로 간단히 언급해야합니다. 그러나 '4 월'이 올해의 네 번째 달이기 때문에 모든 배열의 첫 요소가 0이므로 '[3]'을 언급했습니다.
자바에서는 다음과 같이 할 수 있습니다.
// 자바 타입 variable_name의 선언 []; variable_name = 새 유형 [크기];
여기서는 초기에 배열 변수를 해당 유형으로 선언 한 다음 'new'를 사용하여 메모리를 할당하고 선언 된 배열 변수에 'new'를 할당했습니다. 위의 예제를 취해서 한 해의 각 달에 저울을 포함 할 배열을 선언하고자 할 때.
// 예제 int month_balance []; month_balance = 새로운 int [12];
여기서 'new'는 배열 변수 "month_balance"에 메모리를 할당하므로 이제 mont_balance는 12 개의 정수 값에 대한 메모리를 보유하게됩니다.
배열은 선언 될 때 초기화 될 수 있습니다. 배열 이니셜 라이저는 괄호로 묶은 쉼표로 구분 된 값의 목록입니다.
//예
int month_balance = {100, 500, 200, 750, 850, 250, 630, 248, 790, 360, 450, 180}; 2 차원 배열 (2-D 배열)의 정의
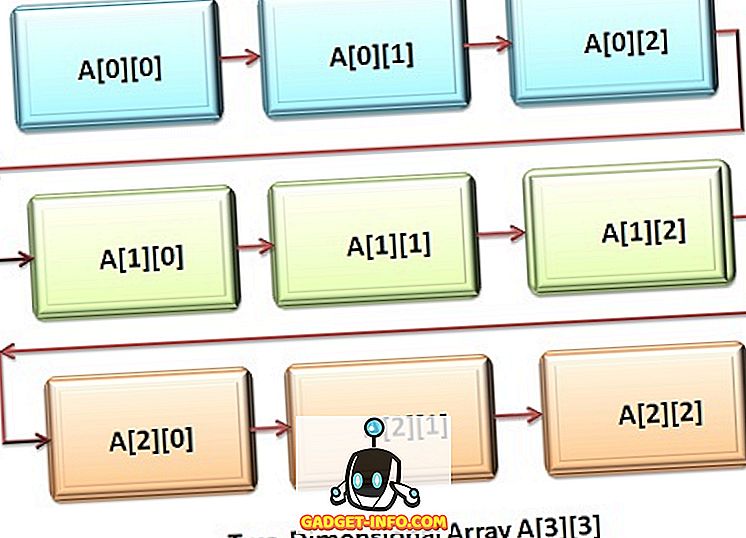
C ++과 Java 모두 다차원 배열을 지원합니다. 다차원 배열의 가장 간단한 형식 중 하나는 2 차원 배열 또는 2 차원 배열입니다. 2 차원 배열은 '배열 배열'또는 '1 차원 배열 배열'로 간주 될 수 있습니다. 2 차원 배열 변수를 선언하려면 두 개의 대괄호가 오는 배열 이름을 지정해야하며 두 번째 인덱스는 대괄호 두 번째 집합입니다.
2 차원 배열은 행 - 열 행렬 형식으로 저장됩니다. 여기서 첫 번째 인덱스는 행을 나타내고 두 번째 인덱스는 열을 나타냅니다. 배열의 두 번째 또는 가장 오른쪽 인덱스는 배열 요소에 액세스하는 동안 첫 번째 또는 가장 왼쪽 인덱스와 비교하여 매우 빠르게 변경됩니다.
// C ++에서의 선언 variable_name [size1] [size2];
예를 들어, 매월 30 일마다의 잔액을 2 차원 배열로 저장하려고합니다.
// 예제 int month_balance [12] [30];
Java에서 2 차원 배열은
// 자바 타입의 선언 variable_name = new int [size1] [size2]; // 예제 int month_balance = new int [12] [30];
전체 배열을 함수의 매개 변수로 전달할 수 없으므로 배열의 첫 번째 요소에 대한 포인터가 전달됩니다. 2 차원 배열을받는 인수는 맨 오른쪽 차원을 정의해야합니다. 배열을 올바르게 색인화하려는 경우 각 행의 길이를 확인하기 위해 컴파일러에 필요하기 때문에 가장 오른쪽 치수가 필요합니다. 가장 오른쪽의 인덱스가 언급되지 않은 경우 컴파일러는 다음 행이 시작되는 위치를 판별 할 수 없습니다.
// Java의 예제 void receiveing_funct (int a [] [10]) {. . . } 메모리가 Java의 2 차원 배열에 동적으로 할당되면 가장 왼쪽의 인덱스가 지정되고 나머지 차원은 별도로 할당 될 수 있습니다. 즉 배열의 모든 행이 같은 크기가 아닐 수 있습니다.
// 자바에서의 예제 int month_balance = new int [12] []; month_balance [0] = 새로운 int [31]; month_balance [1] = 새로운 int [28]; month_balance [2] = 새로운 int [31]; month_balance [3] = 새로운 int [30]; month_balance [4] = 새로운 int [31]; month_balance [5] = 새로운 int [30]; month_balance [6] = 새로운 int [31]; month_balance [7] = 새로운 int [30]; month_balance [8] = 새로운 int [31]; month_balance [9] = 새로운 int [30]; month_balance [10] = 새로운 int [31]; month_balance [11] = 새로운 int [30]; month_balance [12] = 새로운 int [31];
그러나 그렇게하는 것의 이점은 없습니다.
1 차원 및 2 차원 배열의 주요 차이점
- 1 차원 배열은 요소가 유사한 데이터 유형의 목록입니다. 한편, 2 차원 배열은 요소가 유사한 데이터 유형의 배열 인 목록입니다.
- C ++에서, 1 차원 배열이 수신 함수의 매개 변수에 의해 수신 될 때, 배열의 크기를 언급 할 필요가 없습니다. 컴파일러는 길이의 일부 (매개 변수와 함께 언급 된 데이터 유형)의 배열을 이해합니다. 받을 것이다. 2 차원 배열에서는 컴파일러가 단일 행 끝과 새 행이 시작되는 위치를 알아야하기 때문에 두 번째 또는 맨 오른쪽 인덱스를 지정해야합니다.
- C ++에서 1 차원 배열은 연속 된 메모리 위치에 인덱싱 된 순서로 저장되지만 2 차원 배열은 인접한 메모리 위치에도 저장되지만 2 차원 배열에 여러 행이 있으므로 첫 번째 행 뒤에는 두 번째 행과 세 번째 행이옵니다.
노트 :
두 함수 모두 1 차원 배열과 2 차원 배열을 전달하는 것과 비슷합니다. 즉, 배열의 이름으로 만 전달됩니다.
// 예제 pass_funt (name_of_array);
결론:
1 차원 및 2 차원 배열 모두에서 인덱스는 배열의 요소를 구체적으로 식별하는 유일한 요소이기 때문에 매우 중요한 역할을합니다. 1 차원 및 2 차원 배열은 선언시에 초기화 될 수 있습니다.