Excel 스프레드 시트에는 데이터 입력을 단순화 및 / 또는 표준화하기위한 셀 드롭 다운이 포함되는 경우가 많습니다. 이 드롭 다운은 데이터 유효성 검사 기능을 사용하여 허용되는 항목의 목록을 지정하여 생성됩니다.
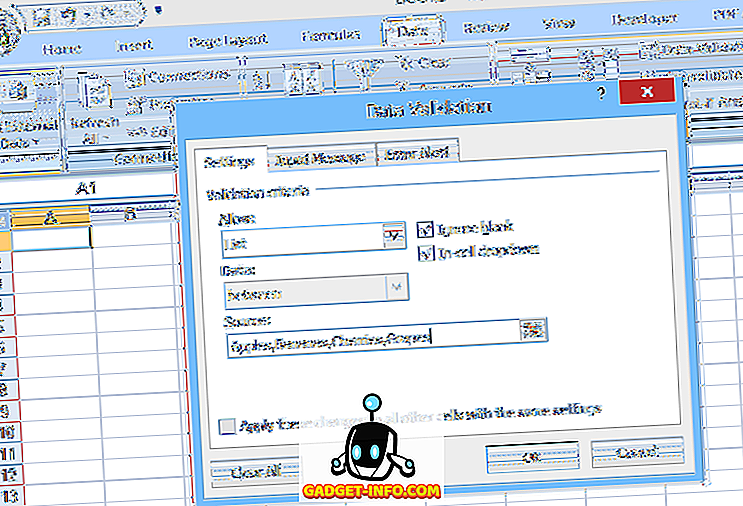
간단한 드롭 다운 목록을 설정하려면 데이터를 입력 할 셀을 선택한 다음 데이터 탭에서 데이터 유효성 검사 를 클릭하고 데이터 유효성 검사를 선택한 다음 허용 목록 아래에서 목록을 선택하고 쉼표로 구분 된 목록 항목을 입력하십시오 ) (그림 1 참조).
이 기본 드롭 다운 유형에서는 허용되는 항목 목록이 데이터 유효성 검사 자체 내에서 지정됩니다. 따라서 목록을 변경하려면 사용자가 데이터 유효성 검사를 열고 편집해야합니다. 그러나 경험이없는 사용자 또는 선택 목록이 길면 어려울 수 있습니다.
또 다른 옵션은 스프레드 시트의 명명 된 범위에 목록을 배치 한 다음 데이터 유효성 검사의 소스 : 필드에 범위 이름 (등호 앞에)을 지정하는 것입니다 (그림 2 참조).
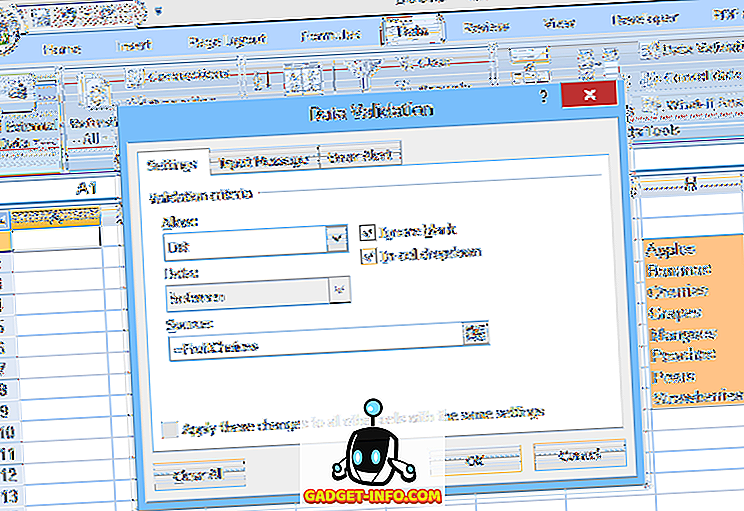
이 두 번째 방법을 사용하면 목록의 선택 사항을 쉽게 편집 할 수 있지만 항목을 추가하거나 제거하면 문제가 발생할 수 있습니다. 명명 된 범위 (여기서는 FruitChoices)가 고정 된 셀 범위 ($ H $ 3 : $ H $ 10)를 나타 내기 때문에 H11 또는 H11 셀에 더 많은 선택 사항이 추가되면 드롭 다운에 나타나지 않습니다 (그 셀은 FruitChoice 범위의 일부가 아니기 때문에).
마찬가지로, 예를 들어 Pears and Strawberries 항목이 지워지면 더 이상 드롭 다운에 나타나지 않지만 드롭 다운은 빈 셀 H9와 FruitChoices 범위를 여전히 참조하기 때문에 드롭 다운에 두 개의 "빈"선택 사항이 포함됩니다 H10.
이러한 이유로 인해 드롭 다운의 목록 소스로 일반 명명 된 범위를 사용하는 경우 항목이 목록에 추가되거나 목록에서 삭제 된 경우 더 많은 또는 더 적은 셀을 포함하도록 명명 된 범위 자체를 편집해야합니다.
이 문제점에 대한 해결책은 동적 범위 이름을 드롭 다운 선택 사항의 소스로 사용하는 것입니다. 동적 범위 이름은 항목이 추가되거나 제거 될 때 데이터 블록의 크기와 정확히 일치하도록 자동으로 확장 (또는 축소)하는 이름입니다. 이렇게하려면 셀 주소의 고정 된 범위가 아닌 수식 을 사용하여 명명 된 범위를 정의합니다.
Excel에서 동적 범위를 설정하는 방법
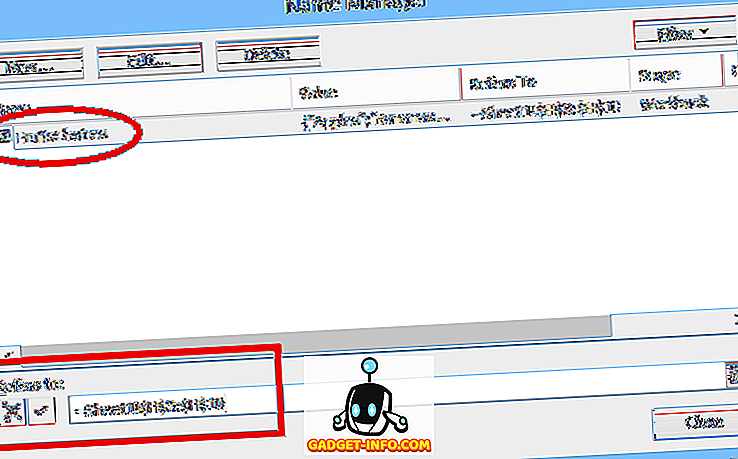
정상 (정적) 범위 이름은 지정된 셀 범위 (이 예에서는 $ H $ 3 : $ H $ 10, 아래 참조)를 나타냅니다.
그러나 동적 범위는 수식을 사용하여 정의됩니다 (아래 참조, 동적 범위 이름을 사용하는 별도의 스프레드 시트에서 가져옴).
시작하기 전에 Excel 예제 파일 (정렬 매크로가 비활성화 됨)을 다운로드했는지 확인하십시오.
이 수식을 자세히 살펴 보겠습니다. Fruits의 선택은 표제 ( FRUITS ) 바로 아래의 셀 블록에 있습니다. 해당 제목에도 이름이 지정됩니다. FruitsHeading :
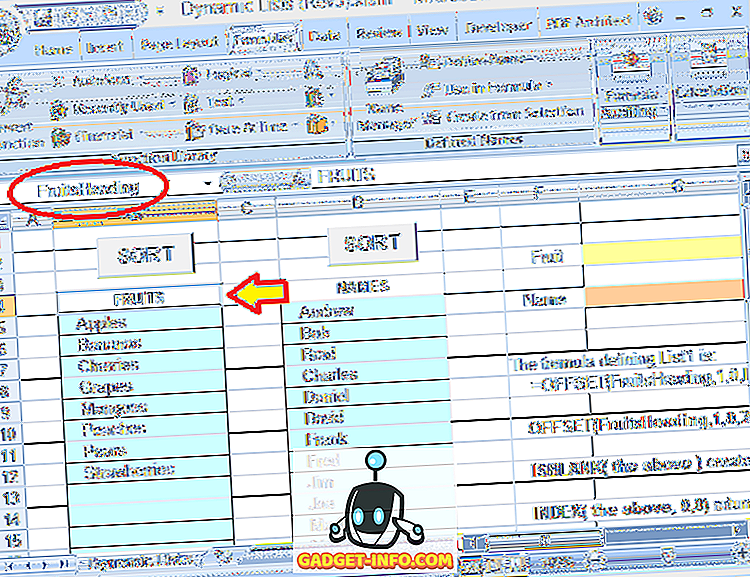
과일 선택의 동적 범위를 정의하는 데 사용되는 전체 수식은 다음과 같습니다.
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK (OFFSET (FruitsHeading, 1, 0, 20, 1)), 0, 0), 0) -1, 20), 1)
FruitsHeading 은 목록의 첫 번째 항목 위에 한 행의 표제를 나타냅니다. 수식에서 두 번 사용되는 숫자 20은 목록의 최대 크기 (행 수)입니다 (원하는대로 조정할 수 있음).
이 예에서는 목록에 8 개의 항목 만 있지만 그 아래에 추가 항목을 추가 할 수있는 빈 셀이 있습니다. 숫자 20은 실제 항목 수가 아닌 항목을 작성할 수있는 전체 블록을 나타냅니다.
이제 수식을 조각 (각 조각을 색으로 구분)으로 분해하여 작동 원리를 이해해 봅시다.
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK ( OFFSET (FruitsHeading, 1, 0, 20, 1) ), 0, 0), 0) -1, 20), 1)
"가장 안쪽"조각은 OFFSET (FruitsHeading, 1, 0, 20, 1) 입니다. 이것은 선택이 입력 될 수있는 20 개의 셀 (FruitsHeading 셀 아래)의 블록을 참조합니다. 이 OFFSET 함수는 기본적으로 다음과 같이 말합니다. FruitsHeading 셀에서 시작하여 1 행과 0 열로 이동 한 다음 길이가 20 행 1 열인 영역을 선택합니다. 그래서 우리에게 과일 선택이 들어간 20 줄 블록이 생깁니다.
공식의 다음 부분은 ISBLANK 함수입니다.
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX ( ISBLANK (위), 0, 0), 0) -1, 20), 1)
여기에서 OFFSET 함수 (위 설명)가 "the"로 바뀌 었습니다 (읽기 쉽도록하기 위해). 그러나 ISBLANK 함수는 OFFSET 함수가 정의하는 셀의 20 행 범위에서 작동합니다.
그런 다음 ISBLANK는 20 개의 TRUE 및 FALSE 값 집합을 생성하여 OFFSET 함수가 참조하는 20 행 범위의 개별 셀 각각이 비어 있는지 (비어 있음) 여부를 나타냅니다. 이 예제에서 첫 번째 8 개의 셀은 비어 있지 않으며 마지막 12 개의 값은 TRUE이므로 집합의 처음 8 개 값은 FALSE가됩니다.
공식의 다음 부분은 INDEX 함수입니다.
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (상기, 0, 0), 0) -1, 20), 1)
다시, "위"는 위에서 설명한 ISBLANK 및 OFFSET 함수를 나타냅니다. INDEX 함수는 ISBLANK 함수에 의해 생성 된 20 개의 TRUE / FALSE 값을 포함하는 배열을 반환합니다.
INDEX 는 일반적으로 특정 행과 열 (해당 블록 내)을 지정하여 데이터 블록에서 특정 값 (또는 값 범위)을 선택하는 데 사용됩니다. 그러나 행 및 열 입력을 0으로 설정하면 (여기 에서처럼) INDEX는 전체 데이터 블록을 포함하는 배열을 반환합니다.
다음 수식은 MATCH 함수입니다.
= OFFSET (FruitsHeading, 1, 0, IFERROR ( MATCH (TRUE, the, 0) -1, 20), 1)
MATCH 함수는 INDEX 함수가 리턴 한 배열 내에서 첫 번째 TRUE 값의 위치를 리턴합니다. 목록의 처음 8 개 항목이 비어 있지 않으므로 배열의 처음 8 개 값은 FALSE가되고 9 번째 값은 TRUE가됩니다 (범위의 9 번째 행이 비어 있기 때문에).
따라서 MATCH 함수는 9 의 값을 리턴합니다. 그러나이 경우 목록에 얼마나 많은 항목이 있는지 알고 싶기 때문에 수식은 MATCH 값 (마지막 항목의 위치를 나타냄)에서 1을 뺍니다. 궁극적으로 MATCH (TRUE, the, 0) -1은 8 의 값을 반환합니다.
공식의 다음 부분은 IFERROR 함수입니다.
= OFFSET (FruitsHeading, 1, 0, IFERROR (the, 20), 1)
IFERROR 함수는 지정된 첫 번째 값의 결과가 오류 일 경우 대체 값을 반환합니다. 이 함수는 셀 전체 블록 (20 행 모두)이 항목으로 채워지면 MATCH 함수가 오류를 반환하기 때문에 포함됩니다.
이것은 MATCH 함수가 ISBLANK 함수의 값 배열에서 첫 번째 TRUE 값을 찾도록 지시하기 때문입니다. 그러나 NONE 셀이 비어 있으면 전체 배열은 FALSE 값으로 채워집니다. MATCH가 검색중인 배열에서 목표 값 (TRUE)을 찾지 못하면 오류를 반환합니다.
따라서 전체 목록이 꽉 차면 (따라서 MATCH에서 오류를 반환하는 경우) IFERROR 함수는 값 20을 반환합니다 (목록에 20 개의 항목이 있어야 함을 알고 있음).
마지막으로, OFFSET (FruitsHeading, 1, 0, the above, 1) 은 우리가 실제로 찾고있는 범위를 반환합니다. FruitsHeading 셀에서 시작하여 1 행 아래로 이동 한 다음 0 행 이상으로 이동 한 다음 길이가 긴 행을 선택합니다. 목록에 항목이 있습니다 (너비가 1 열). 따라서 전체 수식은 실제 항목 만 포함하는 범위 (첫 번째 빈 셀까지)를 반환합니다.
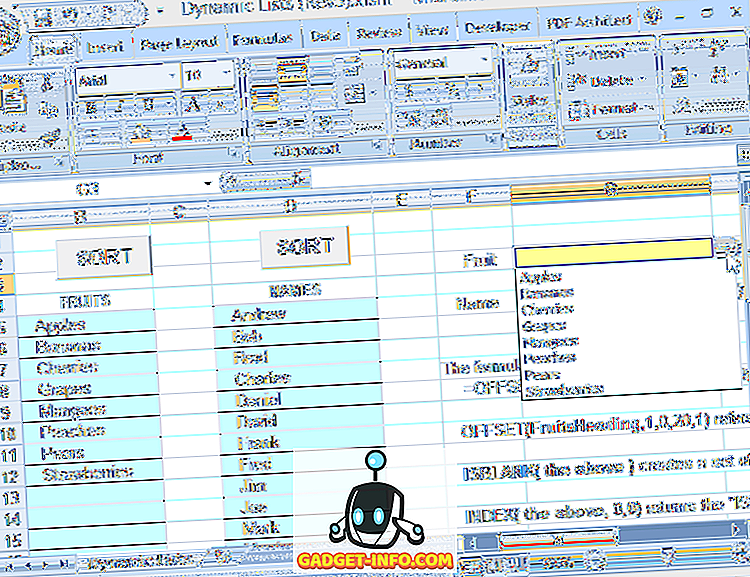
이 수식을 사용하여 드롭 다운의 원본 범위를 정의하면 목록을 자유롭게 편집 할 수 있습니다 (나머지 항목이 맨 위 셀에서 시작하여 인접한 경우 엔 항목 추가 또는 제거가 가능함). 드롭 다운은 항상 현재 항목을 반영합니다 목록 (그림 6 참조).
여기에 사용 된 예제 파일 (동적 목록)이 포함되어 있으며이 웹 사이트에서 다운로드 할 수 있습니다. 그러나 WordPress에서는 매크로가있는 Excel 서적을 좋아하지 않기 때문에 매크로가 작동하지 않습니다.
목록 블록의 행 수를 지정하는 대신 목록 블록에 고유 한 범위 이름을 할당 할 수 있으며 수정 된 수식에서 사용할 수 있습니다. 예제 파일에서 두 번째 목록 (Names)은이 메서드를 사용합니다. 여기서 전체 목록 블록 ( "NAMES"제목 아래, 예제 파일의 40 개 행)에는 NameBlock 의 범위 이름이 지정 됩니다. NamesList를 정의하는 대체 수식은 다음과 같습니다.
= OFFSET (NamesHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK ( NamesBlock ), 0, 0), 0) -1, ROWS (NamesBlock )
여기서 NamesBlock 은 OFFSET (FruitsHeading, 1, 0, 20, 1 )을 대체하고 ROWS (NamesBlock) 는 이전 수식에서 20 (행 수 )를 대체합니다.
따라서 쉽게 편집 할 수있는 드롭 다운 목록 (경험이 없을 수있는 다른 사용자 포함)에 대해서는 동적 범위 이름을 사용해보십시오! 그리고이 기사에서는 드롭 다운 목록에 초점을 맞추었지만 동적 범위 이름은 크기가 다를 수있는 범위 또는 목록을 참조해야하는 곳이면 어디에서나 사용할 수 있습니다. 즐겨!